










UniAnimate
Efficient model for generating consistent character video animation
Tags:Ai video toolsAI video generation toolsPreview:
Introduce:
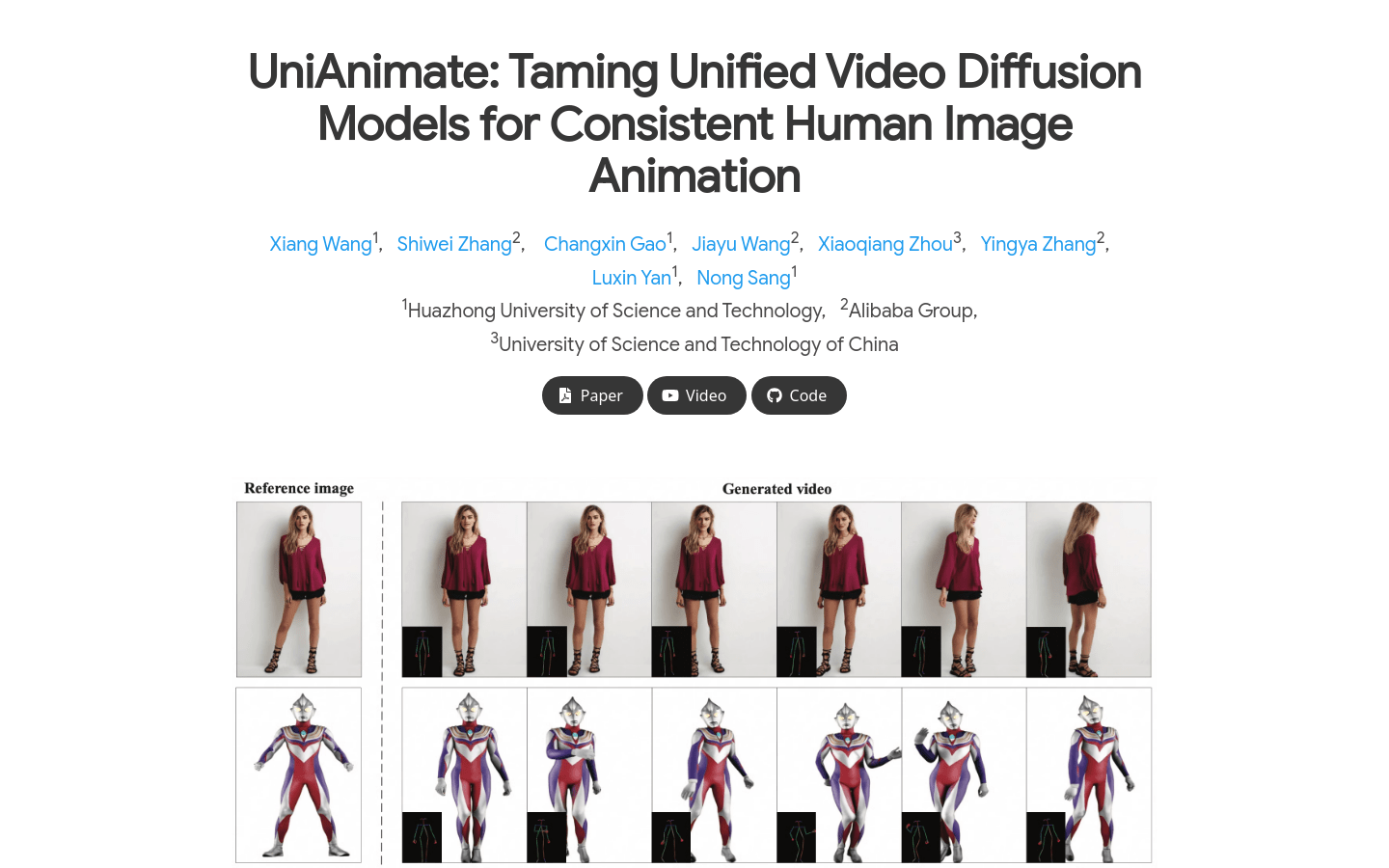
UniAnimate is a unified video diffusion model framework for the animation of human images. It works by mapping reference images, postural instructions, and noisy video into a common feature space to reduce optimization difficulty and ensure coherence over time. UniAnimate is capable of handling long sequences and supports random noise input and first-frame conditional input, significantly improving its ability to generate long-term video. In addition, it explores alternative time modeling architectures based on state space models to replace the original computationally intensive time Transformer. UniAnimate has achieved synthetic results that outperform existing state-of-the-art technologies in both quantitative and qualitative evaluations, and is able to generate highly consistent one-minute videos iteratively using first-frame condition strategies.
Stakeholders:
UniAnimate’s target audience is primarily researchers and developers in the field of computer vision and graphics, especially those professionals who focus on character animation and video generation. It is suitable for application scenarios that need to generate high-quality, long sequence character video animation, such as film production, game development, virtual reality experience, etc.
Usage Scenario Examples:
- Use UniAnimate to generate high quality character animation for movie production.
- In game development, UniAnimate is used to generate coherent character action sequences.
- Create realistic character dynamics in a virtual reality experience with UniAnimate.
The features of the tool:
- CLIP encoders and VAE encoders are used to extract potential features of a given reference image.
- The representation of the reference pose is incorporated into the final reference guide to facilitate learning of the human structure in the reference image.
- A postural encoder is used to encode the goal-driven postural sequence and connect the noise input along the channel dimension.
- The connected noise inputs are stacked with reference guides along the time dimension and fed into the unified video diffusion model to remove noise.
- In the unified video diffusion model, the time module can be a time Transformer or a time Mamba.
- The VAE decoder is used to map the generated potential video into the pixel space.
Steps for Use:
- First, prepare a reference image and a series of target pose sequences.
- CLIP encoders and VAE encoders were used to extract potential features of reference images.
- The representation of the reference posture is combined with the underlying characteristics to form a reference guide.
- The target pose sequence is encoded by the pose encoder and combined with the noise video.
- The combined input data is fed into the unified video diffusion model for noise removal.
- Choose a time module as needed, either Time Transformer or Time Mamba.
- Finally, the VAE decoder is used to convert the processed potential video into a pixel-level video output.
Tool’s Tabs: Character animation, video generation
